


使用TensorFlow 来实现一个简单的验证码识别过程
文 / Mob 技术专家 孙尧
本文我们来用 TensorFlow 来实现一个深度学习模型,用来实现验证码识别的过程,这里识别的验证码是图形验证码,首先我们会用标注好的数据来训练一个模型,然后再用模型来实现这个验证码的识别。
1.验证码准备
这里我们使用 python 的 captcha 库来生成即可,这个库默认是没有安装的,所以这里我们需要先安装这个库,另外我们还需要安装 pillow 库

安装好之后,我们就可以用如下代码来生成一个简单的图形验证码
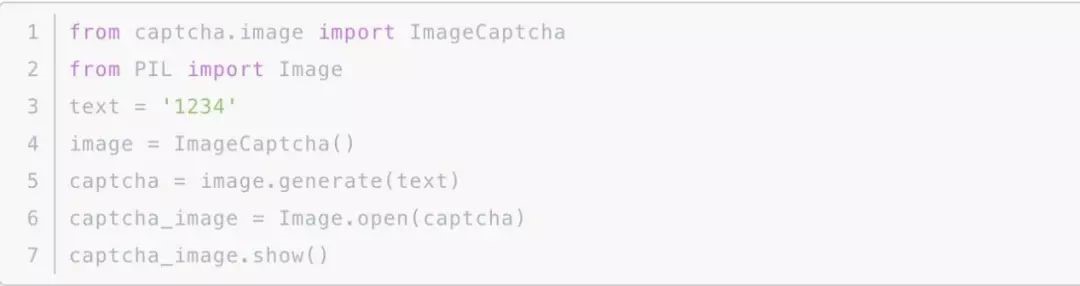

可以看到图中的文字正是我们所定义的内容,这样我们就可以得到一张图片和其对应的真实文本,接下来我们就可以用它来生成一批训练数据和测试数据了。
2.预处理
在训练之前肯定是要进行数据预处理了,现在我们首先定义好了要生成的验证码文本内容,这就相当于已经有了 label 了,然后我们再用它来生成验证码,就可以得到输入数据 x 了,在这里我们首先定义好我们的输入词表,由于大小写字母加数字的词表比较庞大,设想我们用含有大小写字母和数字的验证码,一个验证码四个字符,那么一共可能的组合是 (26 + 26 + 10) ^ 4 = 14776336 种组合,这个数量训练起来有点大,所以这里我们精简一下,只使用纯数字的验证码来训练,这样其组合个数就变为 10 ^ 4 = 10000 种,显然少了很多。
所以在这里我们先定义一个词表和其长度变量:

这里 VOCAB 就是词表的内容,即 0 到 9 这 10 个数字,验证码的字符个数即 CAPTCHA_LENGTH 是 4,词表长度是 VOCAB 的长度,即 10。
接下来我们定义一个生成验证码数据的方法,流程类似上文,只不过这里我们将返回的数据转为了 Numpy 形式的数组:

这样调用此方法,我们就可以得到一个 Numpy 数组了,这个其实是把验证码转化成了每个像素的 RGB,我们调用一下这个方法试试:

内容如下:

可以看到它的 shape 是 (60, 160, 3),这其实代表验证码图片的高度是 60,宽度是 160,是 60 x 160 像素的验证码,每个像素都有 RGB 值,所以最后一维即为像素的 RGB 值。
接下来我们需要定义 label,由于我们需要使用深度学习模型进行训练,所以这里我们的 label 数据最好使用 One-Hot 编码,即如果验证码文本是 1234,那么应该词表索引位置置 1,总共的长度是 40,我们用程序实现一下 One-Hot 编码和文本的互相转换:

这里 text2vec() 方法就是将真实文本转化为 One-Hot 编码,vec2text() 方法就是将 One-Hot 编码转回真实文本。
例如这里调用一下这两个方法,我们将 1234 文本转换为 One-Hot 编码,然后在将其转回来:

这样我们就可以实现文本到 One-Hot 编码的互转了。
接下来我们就可以构造一批数据了,x 数据就是验证码的 Numpy 数组,y 数据就是验证码的文本的 One-Hot 编码,生成内容如下:
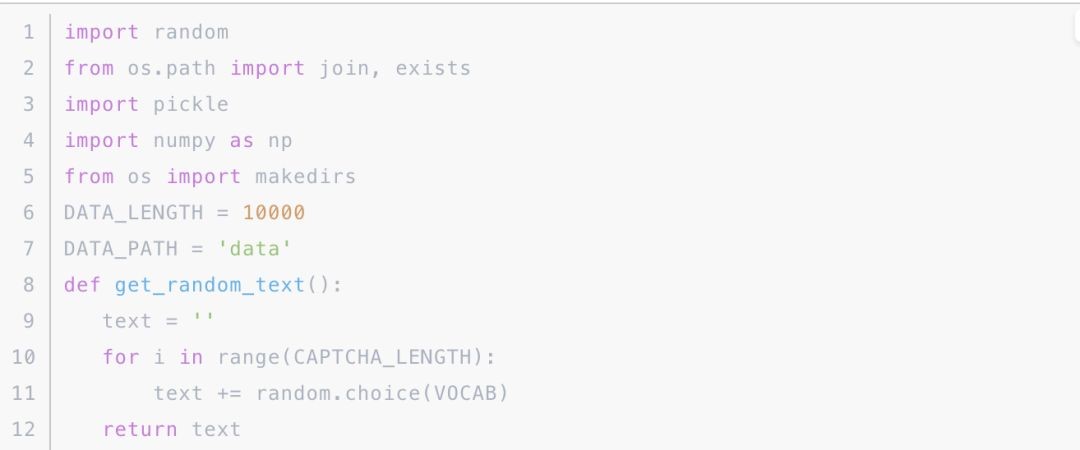
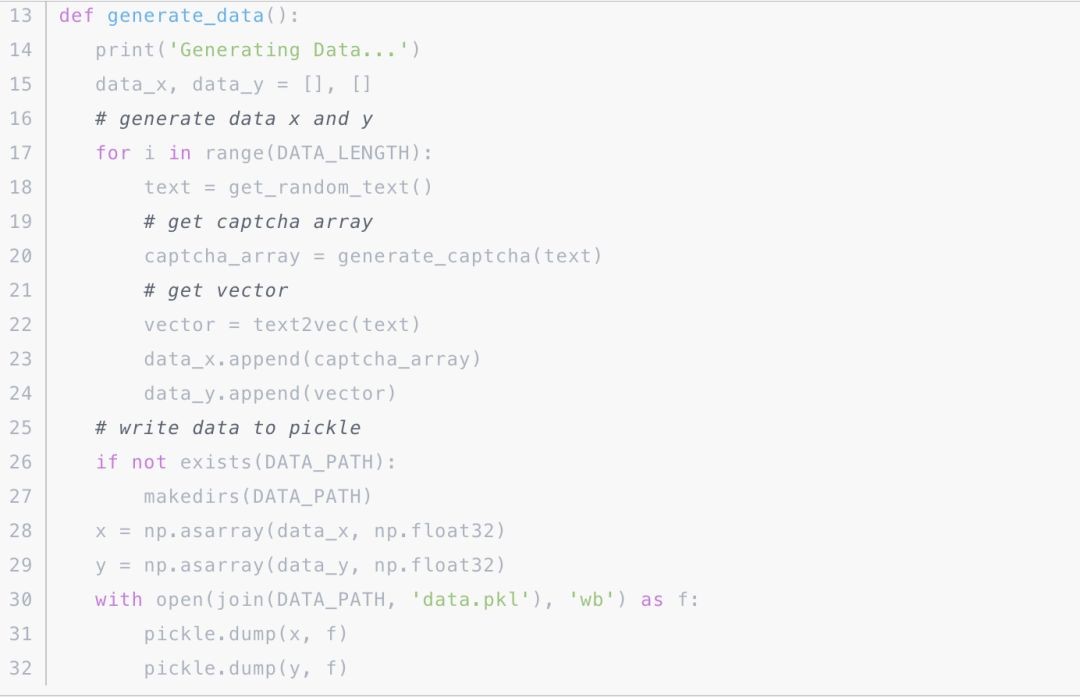
这里我们定义了一个 getrandomtext() 方法,可以随机生成验证码文本,然后接下来再利用这个随机生成的文本来产生对应的 x、y 数据,然后我们再将数据写入到 pickle 文件里,这样就完成了预处理的操作。
3.构建模型
有了数据之后,我们就开始构建模型吧,这里我们还是利用 traintestsplit() 方法将数据分为三部分,训练集、开发集、验证集:

接下来我们使用者三个数据集构建三个 Dataset 对象:

然后初始化一个迭代器,并绑定到这个数据集上:

接下来就是关键的部分了,在这里我们使用三层卷积和两层全连接网络进行构造,在这里为了简化写法,直接使用 TensorFlow 的 layers 模块:
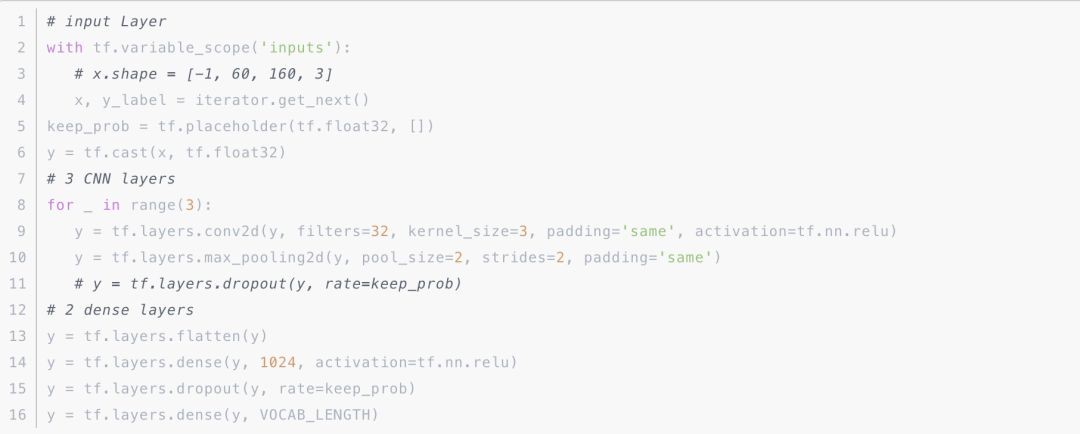
这里卷积核大小为 3,padding 使用 SAME 模式,激活函数使用 relu。
经过全连接网络变换之后,y 的 shape 就变成了 [batchsize, nclasses],我们的 label 是 CAPTCHALENGTH 个 One-Hot 向量拼合而成的,在这里我们想使用交叉熵来计算,但是交叉熵计算的时候,label 参数向量最后一维各个元素之和必须为 1,不然计算梯度的时候会出现问题。详情参见 TensorFlow 的官方文档:
https://www.tensorflow.org/apidocs/python/tf/nn/softmaxcrossentropywithlogits
但是现在的 label 参数是 CAPTCHALENGTH 个 One-Hot 向量拼合而成,所以这里各个元素之和为 CAPTCHALENGTH,所以我们需要重新 reshape 一下,确保最后一维各个元素之和为 1:

这样我们就可以确保最后一维是 VOCAB_LENGTH 长度,而它就是一个 One-Hot 向量,所以各元素之和必定为 1。
然后 Loss 和 Accuracy 就好计算了:

再接下来执行训练即可:
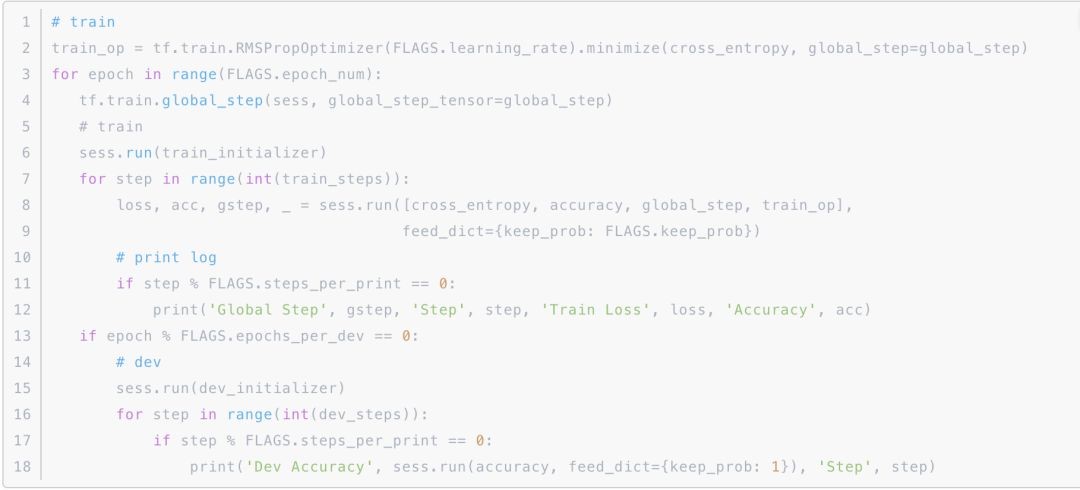
在这里我们首先初始化 traininitializer,将 iterator 绑定到 Train Dataset 上,然后执行 trainop,获得 loss、acc、gstep 等结果并输出。
训练
运行训练过程,结果类似如下:
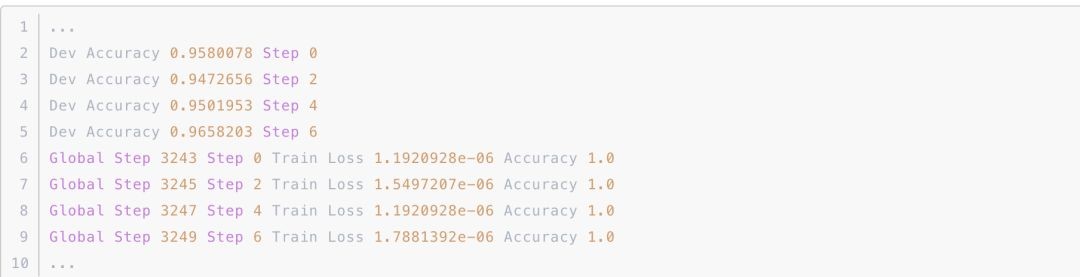
测试
训练过程我们还可以每隔几个 Epoch 保存一下模型:

当然也可以取验证集上准确率最高的模型进行保存。
验证时我们可以重新 Reload 一下模型,然后进行验证:
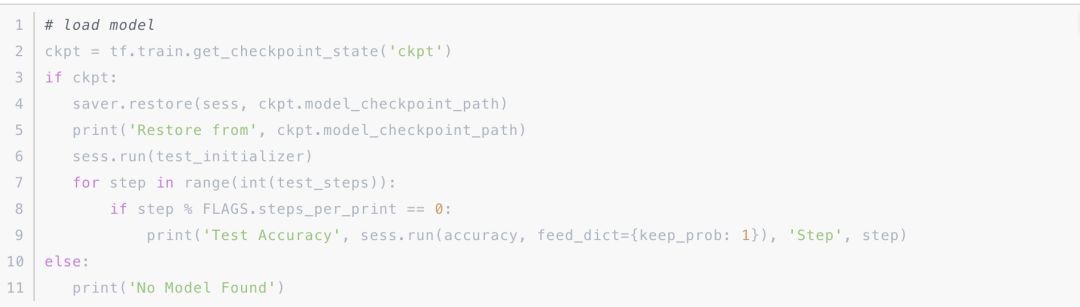



- 2018-09-03 12:03:26
- 2018-09-05 12:25:50
- 2018-09-07 14:47:50
- 2018-11-16 18:12:09
- 2018-12-06 14:12:34


